Deep Neural Networks for Multiclass Classification with Keras and PyTorch Lightning
- Oct 25, 2023
- 18 min read
Updated: May 24, 2024

This is a step-by-step guide on how to implement a deep neural network (DNN) for multiclass classification with Keras from TensorFlow and PyTorch Lightning.
Table of contents
1. Brief introduction to multiclass classification
Suppose we have some data for which we know we can classify/group it in k classes. We have data for which we know their correct classification but we wish to classify any future un-classified data. In that case, we have a clasification problem, and if k is larger than 2, we say it is a multiclass classification problem.
In this article, our task is to train a model to accurately predict to which class/group a data point belongs to by using variables (known as features) known to be pertinent for classifying our data.
There are several models that can be used for multiclass classification. In this article, we will use a deep neural network (DNN).
Note: If your data are images or text, you probably need Convolutional Neural Networks (CNN) instead.
2. Dependencies
This is the full list of libraries that are needed to run all the examples in this article:
numpy
pandas
keras from tensorflow
torch
torchmetrics
pytorch-lightning
sklearn
matplotlib
seabornHow to install TensorFlow and Keras:
pip install tensorflowHow to install PyTorch and PyTorch Lightning:
pip install torch torchmetrics pytorch-lightningHow to install scikit-learn:
pip install scikit-learn3. Case study
3.1 Introduction and data generation
Suppose we have some data with only two features (x,y). We know that the data can be classified into k classes. We have some previously classified data but we wish to be able to have a model to predict the label.
For this example, we will generate the data that we will use as an example for the DNN-based multiclass classifier that we will implement in Keras and PyTorch. We will define a function (create_data()) which will create fake data associated to k classes.
Let's first import all the libraries and functions we need to create the data and visualize it:
import numpy as np
import matplotlib.pyplot as plt
from numpy.random import uniform, choice, normalHere is the create_data() function:
def create_data(
k: int, # number of classes
npoints: int, # total number of points to be generated
seed: int = 1 # seed for reproducibility
) -> tuple[np.array, np.array]:
"""
Randomly create npoints data points classified into k classes
"""
# Set seed for reproducibility
np.random.seed(seed)
X = [] # collect data
labels = [] # collect class labels
# Randomly define a centroid for each class
x_centers = {i: uniform(25, 100) for i in range(k)}
y_centers = {i: uniform(0, 1000000) for i in range(k)}
# Generate npoints
for ipoint in range(npoints):
# Randomly assign this point to a class
ik = choice(range(k))
labels.append(ik)
# Retrieve centroid for this class
center_x = x_centers[ik]
center_y = y_centers[ik]
# Generate point
X.append([
normal(center_x, 3),
normal(center_y, 15000)
])
return np.array(X), np.array(labels)Now let's create 100 data points associated to three different classes:
data, labels = create_data(k=3, npoints=100)We will now define a function that we will use to visualize the data:
def make_scatter_plot(
data: np.array, # 2D array
labels: np.array, # 1D array with class labels
k: int, # number of classes
outname: str # output name
) -> None:
""" Make scatter plot"""
# Protection
assert k < 9, "Only up to 8 classes are supported"
# Define colors for each class
colors = {
0: 'red',
1: 'black',
2: 'blue',
3: 'green',
4: 'yellow',
5: 'orange',
6: 'magenta',
7: 'cyan',
}
# Plot data from each class
title = outname.split('.')[0]
plt.figure(title)
plt.title(title)
for ik in range(k): # loop over classes
# Get data for class ik
data_k = data[labels == ik]
# Unpack data (age and income)
X = list(zip(*data_k))
x, y = X[0], X[1]
# Make scatter plot and add x- and y-axis titles
plt.scatter(x, y, c = colors[ik])
# Save figure
plt.savefig(outname)Now, use the above function to visualize the data:
make_scatter_plot(data=data, labels=labels, k=3, outname='data.png')The above will produce the following figure:

3.2 Data preparation
Our labels are nominal numbers. We should treat them as if they were names (i.e. text). In order to ensure the neural network does not interpret the labels as ordinal numbers (i.e. numerical order has a meaning), we will use the so-called one-hot encoding technique. In this technique, each label is converted to a vector of integers where only one item is 1 while the rest are zero. The size of the vector is equal to the number of classes and each class is converted to the exact same vector. For example, 0 can be converted to [1, 0, 0], 1 to [0, 1, 0] and 2 to [0, 0, 1]. In Python, we can do this conversion in the following way:
from tensorflow import keras
labels = labels.reshape(-1, 1)
labels = keras.utils.to_categorical(y=labels, num_classes=3)Note: In this example, we are using an integer to identify each class. If our classes are identified by a string (i.e. text), we can still use the exact same to_categorical() function.
FYI: We could also have used the OneHotEncoder class from scikit-learn:
from sklearn.preprocessing import OneHotEncoder
labels = labels.reshape(-1, 1)
labels = OneHotEncoder(sparse_output=False).fit_transform(labels)Let's define a function that we will use later to revert the above transformation:
def to_numerical(labels):
""" Revert one-hot encoding """
return np.argmax(labels, axis=1)Furthermore, we need to define the datasets that will be used for training, validating and testing the model. The validation dataset will be used during training, after each training epoch, to measure the model performance. The testing dataset will be used to evaluate the performance of our best model, selected during training based on a metric calculated using validation data. The idea behind using all these datasets is to prevent overfitting and make sure the model performs well on unseen data.
For this example, we will use 30% of the data for testing. Then, from the rest, we will use its 80% for training and the remaining for validation. For this, we can use the train_test_split() function from scikit-learn. We first get the testing data and then use the same function again on the remaining data to get the training and validation data:
from sklearn.model_selection import train_test_split
x_train_tmp, X_test, y_train_tmp, y_test = train_test_split(data, labels, test_size=0.3, random_state=10)
X_train, X_val, y_train, y_val = train_test_split(x_train_tmp, y_train_tmp, train_size=0.8, random_state=10)
Note: I recommend setting shuffle=True. In this case, this was not needed because our data is (by design) already well mixed.
Let's now standardize the data. Standardization scales the features to have a mean of 0 and a standard deviation of 1. This is recommended when features have different scales, as in our case. There are several reasons for standardizing. One reason is to avoid features with larger scales to dominate the training, making it difficult for the model to learn from smaller-scaled features. Technically, we will use the StandardScaler class from scikit-learn:
from sklearn.preprocessing import StandardScaler
def standardize_data(data: tuple[np.array, np.array]) -> tuple[np.array, np.array]:
""" Standarize data using StandardScaler """
scaler = StandardScaler()
data_standardized = scaler.fit_transform(data)
return data_standardizedNow we can use the above function to standardize each one of the datasets separately:
data_dict = {
'training': (X_train, y_train),
'testing': (X_test, y_test),
'validation': (X_val, y_val),
}
standardized_data_dict = {}
for dataset_type, data_tuple in data_dict.items():
data_standardized = standardize_data(data=data_tuple[0])
standardized_data_dict[dataset_type] = (data_standardized, data_tuple[1])Let's now re-use the make_scatter_plot() function and visualize the standardized training dataset:
make_scatter_plot(
data = standardized_data_dict['training'][0],
labels = to_numerical(standardized_data_dict['training'][1]),
k = 3,
outname = 'standardized_training_data.png'
)The above will produce the following figure:

Important:
We standardize each dataset separately to avoid data leakage. Standardization uses the mean and the standard deviation of the data to be standardized. If we standardize the data using the statistics of the full data, we risk introducing information from the validation/testing datasets into the training data, even if we split the standardized data afterwards.
Distribution of classes:
Preferably, we wish each dataset to have a class distribution (i.e. counts proportion per class) similar to each other and to the real class distribution of the population (for simplicity, we will assume it is the same as the complete dataset). If that is not the case in the training data, then this can lead to biased models, where the model may favor the most populated class. Furthermore, if this is the case in the testing or validation data, then the performance measured in those datasets might not generalize well to unseen data.
Let's create a function to compare all class distributions:
def compare_distributions(hists, k) -> None:
""" Compare distributions """
# Protection
assert k < 9, "Only up to 8 classes are supported"
# Define a color for every class
colors = {
0: 'red',
1: 'black',
2: 'blue',
3: 'green',
4: 'yellow',
5: 'orange',
6: 'magenta',
7: 'cyan',
}
# List of data categories
data_categories = hists.keys()
# Prepare the data
data_dict = {}
for i, (data_type, data) in enumerate(hists.items()):
_, values = np.unique(data, return_counts=True) # get counts for every class
data_dict[data_type] = values
# Create numerical axis
x = np.arange(k)
# Set the width of the bars
width = 0.2
# Create figure and axis
fig, ax = plt.subplots()
# Create bars
for i, (data_type, counts) in enumerate(data_dict.items()):
offset = width * i # offset in the x-axis (different for each bar)
bar = ax.bar(x + offset, counts, width=width, label=data_type, color=colors[i])
ax.bar_label(bar) # show numbers on top of bars
# Label the axes
ax.set_xlabel('Class')
ax.set_ylabel('Counts')
# Show category names
ax.set_xticks(x + width, list(range(k)))
# Add legends
ax.legend()
# Save figure
fig.savefig('compare_distribution_of_classes_data.png')Now, we use the function above to compare the class proportions on each dataset:
compare_distributions(
{
'all': to_numerical(labels),
'training': to_numerical(y_train),
'testing': to_numerical(y_test),
'validation': to_numerical(y_val)
},
3
)The above produces the following plot:

All distributions are roughly similar. Although the shape is different in the validation dataset. I don't think the difference is particularly concerning in this case, but if it would, we could use stratified data splits (we just need to set the stratify parameter in the train_test_split() function to the desired class proportions). Alternatively, we could use an oversampling or undersampling technique to artificially balance the class distributions.
4. Implementing a DNN-based multiclass classifier with the Keras API from TensorFlow
4.1. Model creation
In this example, we will use a Sequential model. This is appropriate because we will be implementing a simple stack of layers where each layer has exactly one input tensor (where the input tensor for the first layer will only have two features) and one output tensor (where the last layer will give us a probability distribution over multiple classes).
Note:
For more complex use cases, you will need the Funtional API, which supports arbitrary model architectures. For more information about all Keras APIs, visit https://keras.io/api/models/.
Let's define a function (create_model()) that will create a sequential model for multiclass classification. We will set up a model with two hidden layers. The input and hidden layers will use the popular ReLU (Rectified Linear Unit) activation function. The last layer will use the softmax activation function, in order to obtain a probability distribution over all possible classes. We will use a number of nodes/neurons per layer that works but in a real case, you would have to find optimal values yourself (through an hyperparameter optimization). We will also add the option of adding a dropout layer after the first layer and after the hidden layer. Dropout layers are used to prevent overfitting. A dropout layer randomly drops out a fraction of neurons on each epoch. This is a regularization technique that enables the neural network to become more robust and less dependent on any single neuron or feature, improving its generalization to unseen data. Common values for dropout rates range from 0.2 to 0.5, which also needs to be tuned for each case.
Here is the definition of the create_model() function:
from keras import Sequential
from keras.layers import Dense, Dropout
def create_model(
k: int, # number of classes
dropout_rate: float = 0 # rate for dropout layers
) -> Sequential:
""" Create Sequential model for multiclass classifier """
model = Sequential()
model.add(Dense(16, activation='relu', input_dim=2))
if dropout_rate != 0:
model.add(Dropout(0.5))
model.add(Dense(8, activation='relu'))
if dropout_rate != 0:
model.add(Dropout(0.5))
model.add(Dense(k, activation='softmax'))
return modelFYI:
We use Dense layers, which stand for "densely-connected" layers.
There are two ways of creating the input layer: we can use the InputLayer layer to explicitly define the input layer or we can use Dense and set input_shape on our first hidden layer (what I did).
Now, we create the model using the above function (note that we will not be using dropout layers, which is not necessary in this example):
model = create_model(3)Note:
If you add dropout layers, you might see the validation loss to be systematically smaller than the (training) loss since dropout has only an effect during training, and not for validation.
4.2. Model compilation
Now, we need to compile the model. This step consists in providing settings that determines how the model will be trained. In particular, we have to choose an optimizer, the loss function and any additional metrics that will be used to evaluate the performance of the model.
Optimizer: The optimizer determines how the model's weights will be updated during training. There are various optimizers, in this example, we will use Adam, but you should consider other optimizers as well and choose the one that works better for your case and optimize its parameters (other optimizers are Stochastic Gradient Descent or SGD and RMSprop). Adam employs adaptive learning rates and provides a faster convergence. A learning rate determines the speed at which the model learns from the training data (i.e. the rate at which the model's parameters, weights and biases, are updated).
Loss function: The loss function (also called cost function) is a metric to measure the performance of the model. Specifically, it is a measure of the difference between the predicted value(s) and the true/target values. During training, what we do is to minimize this loss function. Which loss function to use depends on the type of problem. In this case, we should use a Categorical Cross-Entropy loss function.
Metrics: In this example, we will add "accuracy" which measures the fraction of accurate predictions, by comparing for each point, the predicted label (i.e. the label with the highest probability) to the true label.
Here is the a function that compiles our model:
from keras import optimizers
def compile(model: Sequential) -> None:
""" Compile model """
model.compile(
loss = 'categorical_crossentropy',
optimizer = optimizers.Adam(learning_rate=0.001),
metrics = ['accuracy']
)Now, let's compile our model:
compile(model)4.3. Training our model
It's time to train our model. We will first create a train() function where will set the number of epochs (number of times the model sees the entire training data), the training data/labels, the validation data and the callbacks. Callbacks allow us to monitor and control different aspects of the training process. There are a few different possible callbacks, here I will only use EarlyStopping to stop training when the validation loss has stopped improving. This is another technique to prevent overfitting, since the bevaviour of a model that is overfitting is to keep reducing the (training) loss while the validation loss starts to rise.
def train(model, x_train, y_train, val_data):
""" Train model """
# Define callbacks
callbacks = [
# EarlyStopping: Stop training when a val_loss stops improving
keras.callbacks.EarlyStopping(
min_delta = 0.005,
patience = 10,
monitor = 'val_loss',
mode = 'min',
restore_best_weights = True
),
]
return model.fit(
x_train,
y_train,
epochs = 300,
validation_data = val_data,
callbacks = callbacks
)Note:
I'm using the default batch_size which is 32. In your case, you will need to tune this hyperparameter.
We can avoid creating the validation dataset and set the validation_split argument to 0.2 (as long as the training data is full data minus the test data).
Now let's use the function above to train our model:
history = train(
model,
standardized_data_dict['training'][0], # training data
standardized_data_dict['training'][1], # training labels
standardized_data_dict['validation'] # validation data and labels
)Let's create a function that will allow us to visualize the loss and validation loss vs epochs:
import pandas as pd
def plot_loss(history) -> None:
""" Plot loss and val_loss """
history_df = pd.DataFrame(history.history)
plt.figure('loss')
plt.plot(history_df['loss'], label='loss', c='black')
plt.plot(history_df['val_loss'], label='val_loss', c='red')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.savefig('loss.png')Now, let's take a look at how the loss behaved:
plot_loss(history)The above will produce the following figure:

As you can see, the training stops before reaching the specified 300 epochs, since the validation loss stopped improving.
4.4. Performance evaluation
Let's evaluate the accuracy of our trained model in our test data. For that, we will use the evaluate() method of our model:
score = model.evaluate(
standardized_data_dict['testing'][0], # testing data
standardized_data_dict['testing'][1], # testing labels
verbose = 0
)
print('Accuracy in test data:', score[1])Let's get now get predicted labels for our test data using the predict() method from our model:
predictions = model.predict(standardized_data_dict['testing'][0])
labels_predicted = np.argmax(predictions, axis=1) # find class with highest probabilityLet's now compare the labels in our test data (true vs predicted):
# Visualize test dataset with true labels
make_scatter_plot(
data = data_dict['testing'][0], # data for testing
labels = to_numerical(data_dict['testing'][1]), # labels for testing
k = 3,
outname = 'test_data.png'
)
# Visualize test dataset with predicted labels
make_scatter_plot(
data = data_dict['testing'][0], # data for testing
labels = labels_predicted, # predicted labels for test data
k = 3,
outname = 'test_data_predicted_labels.png'
)The above will give us the following figures:
 |  |
As you can see, the predicted labels agree perfectly with the true labels.
Furthermore, we can also make a confusion matrix to evaluate the performance of our classification model. This matrix has the true labels in the y-axis and the predicted labels in the x-axis. Then, it shows the counts for each combination. From this matrix, we can not only know how often the model predicted well the label but also what kind of mistakes the model did.
We can compute a confusing matrix using the confusion_matrix() function from scikit-learn:
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(
to_numerical(data_dict['testing'][1]),
labels_predicted
)We can then make a figure with the retrieved confusion matrix:
import seaborn as sns
def plot_confusion_matrix(cm):
ax = sns.heatmap(cm, annot=True)
ax.set_title('x-axis: predicted labels, y-axis: true labels')
ax.get_figure().savefig('confusion_matrix.png')
plot_confusion_matrix(cm)The above will give you the following confusion matrix:

As you can see, all values are in the diagonal, meaning our model correctly predicted the label for every point in our test data.
4.5. Repository with full code
The full code can be found in the following repository: https://github.com/jbossios/multiclass-classification-keras-example
5. Implementing a DNN-based multiclass classifier with PyTorch Lightning
5.1. Model creation
Now let's use PyTorch Lightning to implement a multiclass classifier using a deep neural network. PyTorch Lightning provides an easy-to-use framework to build and train models.
Let's start by importing all that we will need and setting the seeds:
import numpy as np
from torch import nn, optim, manual_seed, argmax
from torchmetrics.classification import Accuracy, MulticlassConfusionMatrix
import pytorch_lightning as pl
# Set seeds for reproducibility
import random
random.seed(42)
manual_seed(42)
np.random.seed(42)We will create a class (Model) inheriting from the LightningModule class. During initialization, we will be able to provide two parameters
k: the number of classes [mandatory]
dropout_rate: The dropout rate (as with the previous example, we will not use dropout layers but I will show you how to do it) [optional and set by default to zero, i.e. no dropout layers will used]
Our model will rely on a PyTorch Sequential container which will take a list of predefined layers. This container will define the complete architecture of the model. This model will have the same architecture as the one used with Keras. The only difference is that the output layer will not have an activation function. This is because we will use the CrossEntropyLoss loss function from PyTorch, which combines the softmax function with the cross entropy calculation.
The accuracy metric will be computed using the Accuracy module, while the confusion matrix will be computed (during testing) will the MulticlassConfusionMatrix module. This matrix will help us evaluate the model's performance, as done in the previous section.
The Model class will have a forward() method which defines how the data flows through the model. It simply passes the input (x) through the model we defined earlier. While the configure_optimizers() method specifies the optimizer to be used during training. In this case, we will use again Adam. Note that we have to pass the model parameters as well, since this is what the optimizer updates during training.
Finally, we need to define the training_step(), test_step() and validation_step() methods. In these, we will unpack the input batch data into x and y, where x represents the features and y represents the target classes. We will pass the features through the model, compute the loss and any additional metric. Metrics will be tracked using PyTorch Lightning's log method.
Here is the code doing all the above:
class Model(pl.LightningModule):
def __init__(self, k, dropout_rate = 0):
super().__init__()
# Set list of layers in the model
layers = [nn.Linear(2, 16), nn.ReLU()]
if dropout_rate != 0:
layers.append(nn.Dropout(dropout_rate))
layers.extend([nn.Linear(16, 8), nn.ReLU()])
if dropout_rate != 0:
layers.append(nn.Dropout(dropout_rate))
layers.append(nn.Linear(8, k))
# Create model
self.model = nn.Sequential(*layers)
# Define other attributes
self.loss = nn.CrossEntropyLoss()
self.lr = 0.001
self.accuracy = Accuracy(task="multiclass", num_classes=k)
self.test_pred = [] # collect predictions
self.confusion_matrix = MulticlassConfusionMatrix(num_classes=k)
def forward(self, x):
return self.model(x)
def configure_optimizers(self):
return optim.Adam(self.parameters(), lr=self.lr)
def training_step(self, batch, batch_idx):
x, y = batch
logits = self.forward(x)
loss = self.loss(logits, y)
self.log('loss', loss)
# Track accuracy
y_target = argmax(y, dim=1)
y_pred = argmax(logits, dim=1)
acc = self.accuracy(y_pred, y_target)
self.log('accuracy', acc)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
logits = self.forward(x)
loss = self.loss(logits, y)
self.log('val_loss', loss)
# Track accuracy
y_target = argmax(y, dim=1)
y_pred = argmax(logits, dim=1)
acc = self.accuracy(y_pred, y_target)
self.log('val_accuracy', acc)
def test_step(self, batch, batch_idx):
x, y = batch
# Evaluate model
logits = self.forward(x)
# Track loss
loss = self.loss(logits, y)
self.log('test_loss', loss)
# Track accuracy
y_target = argmax(y, dim=1)
y_pred = argmax(logits, dim=1) # find label with highest probability
acc = self.accuracy(y_pred, y_target)
self.log('test_accuracy', acc)
# Collect predictions
self.test_pred.extend(y_pred.cpu().numpy())
# Update confusion matrix
self.confusion_matrix.update(y_pred, y_target)Let's create an instance of our model and print a summary of our model's architecture using the ModelSummary module:
from pytorch_lightning.utilities.model_summary import ModelSummary
model = Model(k=3)
summary = ModelSummary(model, max_depth=-1)
print(summary)The above will print the following:
| Name | Type | Params
---------------------------------------------------------------
0 | model | Sequential | 211
1 | model.0 | Linear | 48
2 | model.1 | ReLU | 0
3 | model.2 | Linear | 136
4 | model.3 | ReLU | 0
5 | model.4 | Linear | 27
6 | loss | CrossEntropyLoss | 0
7 | accuracy | MulticlassAccuracy | 0
8 | confusion_matrix | MulticlassConfusionMatrix | 0
---------------------------------------------------------------
211 Trainable params
0 Non-trainable params
211 Total params
0.001 Total estimated model params size (MB)5.2. Data handling
Now, we will organize and prepare the data for training, validation and testing. For this, we will rely on the LightningDataModule. We will create a class (DataModule) which will inherit from the LightningDataModule and define three data loaders, one for each step (training, validation and testing). Each data loader will be used to load the data and iterate over batches of the corresponding dataset, and rely on the PyTorch's DataLoader class. Technically, we will create a PyTorch Tensor for the input features, and for the target labels. Then, a TensorDataset will be created to hold the data and labels. Here is the code:
from torch import Tensor
from torch.utils.data import TensorDataset, DataLoader
class DataModule(pl.LightningDataModule):
def __init__(self, data_dict: dict, batch_size: int = 32):
super().__init__()
self.data_dict = data_dict
self.batch_size = batch_size
def train_dataloader(self):
X = Tensor(self.data_dict['training'][0])
y = Tensor(self.data_dict['training'][1])
tensor_dataset = TensorDataset(X, y)
return DataLoader(tensor_dataset, batch_size=self.batch_size)
def test_dataloader(self):
X = Tensor(self.data_dict['testing'][0])
y = Tensor(self.data_dict['testing'][1])
tensor_dataset = TensorDataset(X, y)
return DataLoader(tensor_dataset, batch_size=self.batch_size)
def val_dataloader(self):
X = Tensor(self.data_dict['validation'][0])
y = Tensor(self.data_dict['validation'][1])
tensor_dataset = TensorDataset(X, y)
return DataLoader(tensor_dataset, batch_size=self.batch_size)5.3. Training our model
First, we will create a custom callback class (MetricTrackerCallback) to store the loss and accuracy during training and validation. We will define the on_train_epoch_end() method which is called at the end of each training epoch, and the on_validation_epoch_end() method which is called at the end of each validation epoch. In both cases, we will retrieve the logged_metrics dictionary from the trainer (to be explained later) containing all the metrics logged in the training_step() or the test_step() method of our model, as appropriate. Here is the code:
class MetricTrackerCallback(pl.Callback):
def __init__(self):
super().__init__()
self.losses = {
'loss': [],
'val_loss': []
}
self.acc = {
'accuracy': [],
'val_accuracy': []
}
def on_train_epoch_end(self, trainer, module):
metrics = trainer.logged_metrics
self.losses['loss'].append(metrics['loss'])
self.acc['accuracy'].append(metrics['accuracy'])
def on_validation_epoch_end(self, trainer, module):
metrics = trainer.logged_metrics
self.losses['val_loss'].append(metrics['val_loss'])
self.acc['val_accuracy'].append(metrics['val_accuracy'])It's time to talk about the forementioned trainer. In PyTorch Lightning, the trainer simplifies the training process. Under the hood, it handles many things for you, some examples include:
Manages the training loop, ensuring that the model is trained for the specified number of epochs, and it handles the iteration over batches of data, including shuffling the data for each epoch
Automatically enabling/disabling grads
Running the training, validation and test dataloaders
Calling the callbacks at the appropriate times
The following code creates an instance (called tracker) of our MetricTrackerCallback class, sets up the EarlyStopping callback (compatible to what was set in Section 4.3) and the ModelCheckpoint callback (which will allow us to save the best model), and creates a trainer providing all callbacks:
import os
tracker = MetricTrackerCallback()
early_stopping_callback = pl.callbacks.early_stopping.EarlyStopping(
monitor = 'val_loss',
patience = 10,
min_delta = 0.005,
mode = 'min',
)
dirpath = os.path.dirname(__file__) # current path
model_checkpoint_callback = pl.callbacks.ModelCheckpoint(
dirpath = dirpath,
filename = 'best_model',
monitor = 'val_loss',
mode = 'min',
)
trainer = pl.Trainer(
max_epochs = 300,
enable_model_summary = False, # summary printed already
callbacks = [
tracker,
early_stopping_callback,
model_checkpoint_callback
]
)Now the only thing remaining is to create an instance of our DataModule class:
data_module = DataModule(data_dict=standardized_data_dict)Finally, we can train our model in the following way:
trainer.fit(model, data_module)Note: we provide the data module and the trainer uses the correct dataset (the test dataset) using the previously-defined test_dataloader() method.
Now, let's create a function that will allow us to plot the (training) loss and validation loss for every epoch:
import matplotlib.pyplot as plt
def plot_loss(loss_dict) -> None:
""" Plot loss and val_loss """
plt.figure('loss')
plt.plot(loss_dict['loss'], label='loss', c='black')
plt.plot(loss_dict['val_loss'], label='val_loss', c='red')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.savefig('loss.png')Now we use the above function to compare the (training) loss to the validation loss:
plot_loss(tracker.losses) # plot loss vs epochWhich will give us the following figure:

Note that the training is stopped before reaching 300 epochs (thanks to our EarlyStopping callback).
5.4. Performance evaluation
Let's now evaluate the performance of our trained model. As done in Section 4.4, we will evaluate the model in our test data, get predictions and compare them to the target labels:
# Evaluate model in test data and print accuracy
result = trainer.test(model, data_module, ckpt_path="best_model.ckpt")
print(f"Accuracy in test: {result[0]['test_accuracy']}")
# Get predicted labels on test data
labels_predicted = model.test_pred
# Visualize test dataset with true labels
make_scatter_plot(
data = data_dict['testing'][0], # data for testing
labels = to_numerical(data_dict['testing'][1]), # labels for testing
k = 3,
outname = 'test_data.png'
)
# Visualize test dataset with predicted labels
make_scatter_plot(
data = data_dict['testing'][0], # data for testing
labels = np.array(labels_predicted), # predicted labels for test data
k = 3,
outname = 'test_data_predicted_labels.png'
)Note: we rely on the make_scatter_plot() and to_numerical() functions defined in Section 3.2.
The above will give us the following figures:
 | 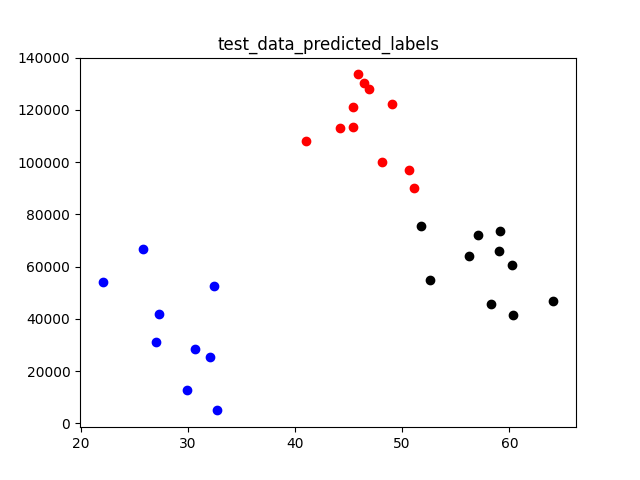 |
which confirms our model works well in unseen data (the test data).
Finally, let's plot the confusion matrix:
fig, _ = model.confusion_matrix.plot()
fig.savefig('confusion_matrix.png')The above will give you the following confusion matrix:

confirming again that the model made no mistake in the test data.
5.5. Repository with full code
The full code can be found in the following repository: https://github.com/jbossios/multiclass-classification-pytorch-lightning-example
Do you wish to learn all the technical skills needed to perform a data analysis in Python? Check out my free Python course for data analysis: https://github.com/jbossios/python-tutorial


